 Krzysztof Maicher
Krzysztof Maicher4 approaches to handling service objects' returns
There is this one common problem with Rails applications - over time ActiveRecord models become too big and too hard to maintain. It happens because they tend to have too many responsibilities. To avoid overloading ActiveRecord models there is a guideline to extract some of the logic to service objects.
Service objects form a layer between controllers and ActiveRecord models, where a certain portion of business logic is places. This approach helps to keep the controller slim and prevents ActiveRecord models from becoming too fat.
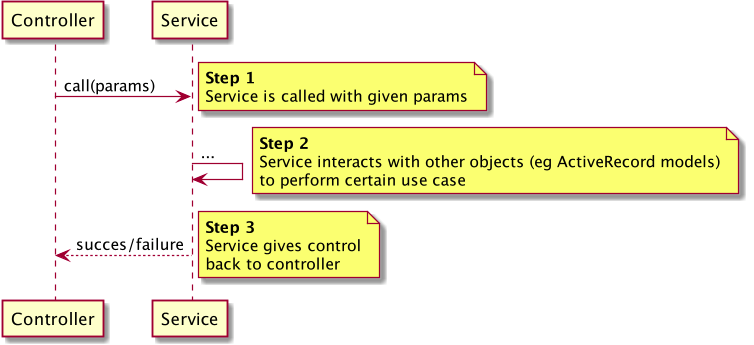
Controller calls a service to perform a certain use case. The service, in turn, interacts with necessary objects (eg. ActiveRecord models) to perform the requested operation, mutating some part of the system’s state. Afterwards, the service returns the control back to the controller>.
I’d like to concentrate on the last step here. What are the possibilities of returning the control from the service object back to the controller?
In my development career I have come across various ways of implementing it and here, I’d like to present a few of them. The use case processing can go in the direction of a happy path or a >sad (exceptional/failure) path>, but the service not only needs to return information if the operation succeeds or fails. Usually additional data needs to be passed as well, so that the controller can handle the response (display a customized message, errors, etc).
All the below examples show the controller calling a service object, but the caller can be anything - a rake task, a background job, a cli, another service, etc.
Handle the sad path by raising and rescuing exceptions
CreateUser service handles the use case of creating a user in an application.
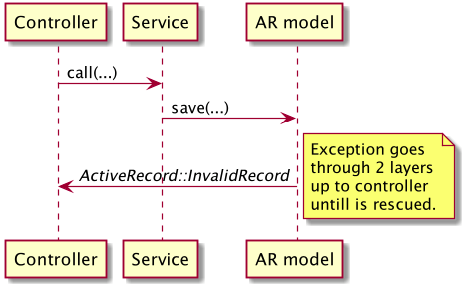
The controller prepares params and calls the service. Then, processing can go in one of two directions. If everything goes fine - the happy path - the service returns a user object which is used in the controller to display a success message. However, if the operation doesn’t succeed - the sad path, things are handled differently. The service raises a custom defined exception and the controller, in turn, rescues this specific exception and displays a failure message.
It’s a normal and expected behaviour that sometimes a service doesn’t process the operation - it can happen e.g. due to invalid params, lack of permissions, etc. There are opinions that those exceptions should not be used in such cases.
For some developers, it’s an antipattern and for others, it’s not. Still, it requires a certain dose of discipline to use it correctly. You need to remember to rescue the specific exception properly, not to let it propagate up the call stack. This problem is often visible in Rails, where it is tempting to rely on already-existing ActiveRecord exceptions:
This code smells because one of the purposes of the CreateUser service is to encapsulate some implementation details inside it - eg. interactions with ActiveRecord. Here, however, the ActiveRecord’s exception class leaks up to the controller, breaking through 2 layers of abstraction.
These and a few other reasons speak against the idea of using exceptions for the sad path. There are better ways to do it. However, the next idea is not one of them yet.
A service returns a boolean
Conditional logic is often used to distinguish between success and failure. Conditionals are free from previously described problems and evaluating them is faster than rescuing exceptions in Ruby.
The controller calls the service and then evaluates conditional logic. The success path is evaluated when the service returned true, otherwise, it takes the failure path. The problem is that it doesn’t scale. If we wanted to handle both paths in a slightly more sophisticated way, we would need to query the service object for additional data.
Now, the service has 3 public methods. Not only the main #call method, which performs the actual operation, but also readers: #user and #error_message. Because the #call method most probably mutates the state of the system, reader methods probably return different values depending on the fact if invoked before or after #call. It can get complicated if they rely on data which is memorized in service’s instance variables. We need to be careful defining these readers and watch out if something doesn’t get memorized in the wrong moment. If it does, readers can return outdated values (memoized before the mutation - #call - happened). So this solution is fragile, there can be situations where it works only if the methods are called in the correct order.
The problem here is that once instantiated, the service object has 2 responsibilities - executing the operation and data containing. The above problems go away if we split these two responsibilities apart.
Class level method and read-only result object
This pattern solves the above problems by providing a separation implemented through a class level method. The operation execution is invoked by calling the class level method. The data is then accessed by readers exposed on the instance of this class.
Class level .call method is defined. Its responsibility is to construct the service object and then execute the operation by calling the #call instance method. So that the controller doesn’t have access to reader methods before the operation is executed.
The problem is that the controller can still access the instance #call method after the operation was performed. The access to the constructor is also not restricted. So along with this implementation, two convention guidelines need to be introduced. First - not to use the call method on the instantiated object. Second - not to use the constructor (use the class level #call method instead).
ActiveInteraction gem provides a DLS which helps to build service objects using the above pattern - fixing these issues.
I’ve been using this pattern for some time. This solution is not ideal though. It comes with a cost of hijacking the constructor. Without the constructor, it’s hard to inject dependencies - collaborators’ objects. So they tend to be hardcoded inside the service definition. Still, we can achieve a dependency injection by passing the collaborators along with the params, however, in my opinion, it’s not an appropriate thing to do - it feels hacky.
Service returns a success or a failure value object
In this solution, we let the service be a regular object, with access to the constructor. We also define two value objects - a Success and a Failure.
In the above example, I’m subclassing the Hash class to define the result value objects, but they can be a PORO (Plain Old Ruby Object) as well. The service returns one of these objects and the controller processes happy or sad paths, based on the type of the returned object.
If we made a decision to use this approach widely across the project, Success and Failure objects could be general purpose ones. There are libraries that take this idea even further - the service can yield the result objects to the block and then >evaluate pattern matching> (a concept from functional programming) so that no conditionals are used to distinguish the paths. If the service returns Success, success block is evaluated. If the service returns Failure - failure block:
Result objects also have a #bind method by which a result object can be chained with another service (or any block of code) in a way that if the first service returns Success, the next service is called. If any service returns Failure - the whole sequence stops executing. This concept is also taken from functional programming and it’s called a monad.
Monads chained together form a pattern called Railway Oriented Programming. Dry-rb libraries (dry-monads, dry-transaction) allow implementing this pattern in Ruby.
We’ve used dry-transaction it one of our clients’ projects within a legacy Rails application to build new features. Services objects implemented using dry-transaction (with help of dry-validation) replaced ActiveInteractors. I found them particularly elegant and flexible.
After I published it on Reddit, different devs shared their ideas on the topic, so the Reddit thread it’s also worth checking: https://www.reddit.com/r/ruby/comments/9znqyg/4_approaches_to_handling_service_objects_returns/