 Krzysztof Maicher
Krzysztof MaicherHow to design a solid database for Rails application
Introduction
From my perspective a poorly designed database can cause a lot of pain when data starts loosing it’s integrity on production.
I’ve seen, that sometimes Rails developers jump into generating ActiveRecord models (using rails generate model ...) without really paying attention how the resulting database will look like.
In this article I’d like to show an opposite approach, by describing my thought process behind designing a piece of database for one application I’ve build lastly. My goal is to point out some details, thanks to which I’m 100% sure to say, that application, based on that database design will never loose it’s data integrity. I invite you to read!
Analyze data
The purpose of the application was to present data (electric and gas meter readings) by charts and tables.
Data, that was stored on FTP by meters, had following characteristics:
- there are around 40 meters, each identified by its unique 18-digit number
- meter measurements are stored on ftp server as a csv file
- each file has about 50 readings (timestamp, meter number and values)
- around 40 new files a day
- that gives around 2k new readings every day
Over a year, the data would grow to 2k x 365, that is around 0.7 million records each year. That is not that much and a properly designed PostgreSQL database should handle that amount of data without performance problems for years. I wanted to store that data in a relational database, that would allow me to easily access it in other part of application, to present it as charts or tables.
Database design upfront
I decided, that the application will interact with database by ActiveRecord. I like ActiveRecord, because of its ease of use. However, when it comes to creating new ActiveRecord models, my approach may be different from other Rails developers.
I like to come up with a database design upfront (in mind, on paper or in some tool) and after that, I start creating ActiveRecord models to satisfy the database design. In other words I design database at first, and then build an ActiveRecord models layer on top of it.
In this case I came up with following database design.
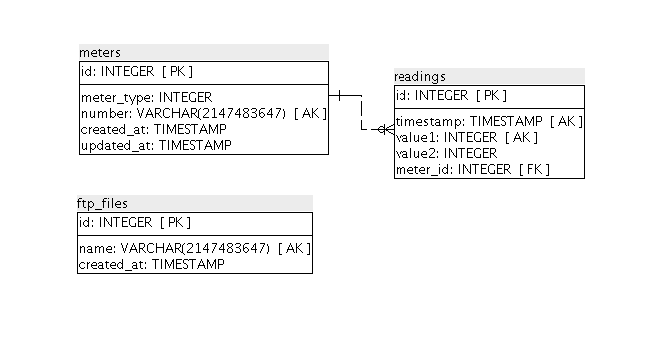
That design is not complex, so I made it in my head before start creating models. However, if more tables with more sophisticated relations would be necessary, I could draw a design on paper or in some tool (eg. SQL Power Architect) before generating models and migrations.
FtpFiles model
At first I came up with ftp_files table. My idea of ftp_files table was to store a list of file names, that have already been parsed. Just a list of file names. It would be pointless to allow keeping there empty names, that’s why I’ve set a not-null constraint. To ensure name uniqueness I could set a unique index or unique constraint. Both ensures uniqueness. Unique index would also improve performance on querying that table by that column, but lower insertions. At this moment, I did not know, whether my application needs an index on that column. I was sure that I need the uniqueness and was not sure if I need index. From my experience, in most cases, when uniqueness is needed, a index is needed as well. So I decided to implemented a unique index there.
Summarizing ftp_files has a name column, that has to be unique and cannot be null.
Having that in head, I ran rails g model FtpFile name:string.
Now, how should the generated migration be adjusted?
1
2
3
4
5
6
7
8
9
10
class CreateFtpFiles < ActiveRecord::Migration
def change
create_table :ftp_files do |t|
t.string :name, nil: false
t.column :created_at, :datetime
end
add_index :ftp_files, :name, unique: true
end
end
Meter model
A meter is identified by it’s number. There has to be only one meter with given number, that’s why I decided to apply a not-null constraints and unique index on number column as well. Having a unique index on that column gives the assurance, that in application, every time a meter will be searched by number, there will be zero or exactly one meter found.
Migrations:
1
2
3
4
5
6
7
8
9
10
11
12
class CreateMeters < ActiveRecord::Migration
def change
create_table :meters do |t|
t.string :number, null: false
t.integer :meter_type, null: true
t.timestamps null: false
end
add_index :meters, :number, unique: true
end
end
Reading model
Reading belongs to meter. Meter has many readings.
One reading consists of 4 values:
- datetime, when it was measured,
- 18-digit meter number,
- two reading values, each representing different tariff. First is always present, second - only sometimes.
In database, I represented that as following columns: timestamp, meter_id, value1, value2. You can go back to the schema above and check it out visually.
It is highly undesirable to double readings in database, because charts created from them would present incorrect values. How to prevent from saving double readings? In PostgreSQL a unique constraints or unique index can be applied to a group of columns.
There is a complete certainty, that when application for any reason (bug, my or some other developers mistake, or even a client’s software problem) will try to insert a doubled reading to database, an exception will be raised (from database level), which is very desirable. I don’t want to see double readings in that database. Unique indexes guarantees it and I can rely on that.
Migration:
1
2
3
4
5
6
7
8
9
10
11
12
class CreateReadings < ActiveRecord::Migration
def change
create_table :readings do |t|
t.integer :value1, null: false
t.integer :value2, null: true
t.datetime :timestamp, null: false
t.integer :meter_id, null: false
end
add_foreign_key :readings, :meters, on_delete: :restrict
end
end
Foreign keys
What is seen in 10’th line in above migration is a foreign key constraint. meters and readings tables are related. A foreign key constraint is a mechanism, that keeps so called referential integrity of that two tables. It prevents inserting reading related to non-existent meter and prevents from deleting meter, that has related readings. In other words, a foreign key constraints prevents the occurrence of orphaned records in readings table.
ActiveRecord validations
Aren’t what ActiveRecord validations are made for? All above mechanisms could be implemented in ActiveRecord models though. I like to use ActiveRecord validations, since they are helpful in generating nice error messages, but there are so many ways of going around them, that they cannot be rely on.
ActiveRecord validations doesn’t guarantee application’s data integrity.
- Because they can be omitted by using following methods:
#save(validate: false), .update_attribute, .delete, .delete_all, .update_all
Since above methods are available in whole application, it’s crazy to assume, that nobody ever will use them!
- Because developer can write to database tables by using raw SQL queries, or even log into psql console to run some updates or inserts.
- Because they always takes few steps to perform, so they are exposed to race conditions in concurrently running code (read Concurrency and integrity section in Rails documentation)
Data integrity
Summarizing, if you want to prevent an application from loosing it’s data integrity, you have to keep security on a database layer. I other words, you have to use database mechanisms to prevent loosing data integrity. ActiveRecord validations can not be rely on. Using ActiveRecord models speeds up the development process, but using them without a solidly designed database can lead to frustrations and to lots of maintenance work, when data will start loosing its integrity in production.
When you aim for a solid database design, learn about foreign keys constraints and start using them. Start using uniqueness validations not only in ActiveRecord models, but at a database layer as well (including unique indexes on groups or inside json fields). Use not-null constraints if column can’t be blank and specify a default value.
In my case, in application, that I described here, I can be sure (unless nobody will modify the database schema), that:
- Readings and meters will not be doubled.
- There will be no readings without a value or timestamp.
- There will be no orphaned records on meters-readings relation.
Furthermore, application can download the data concurrently and when race conditions will occur, they can be handle, because database will inform about that by raising errors.
Having that, the client can rely on the data in that database. Meter readings can be kept there for years, without fear of loosing their consistency.